
Browsing without a GUI#
Puppeteer allows you to control a Chrome or Chromium instance using NodeJs. The real benefit is running Puppeteer as a headless browser, meaning you don't have any GUI to interact with but you can navigate pages, interact with buttons and take screenshots all from your node script. For example:
const puppeteer = require('puppeteer'); async function screenshot() { const browser = await puppeteer.launch({}); const page = await browser.newPage(); await page.goto('https://www.google.com'); await page.screenshot({path: 'GoogleOn' + new Date().toDateString() + '.png'}); browser.close(); } screenshot();Resulting in GoogleOnSun\ Oct\ 17\ 2021.png
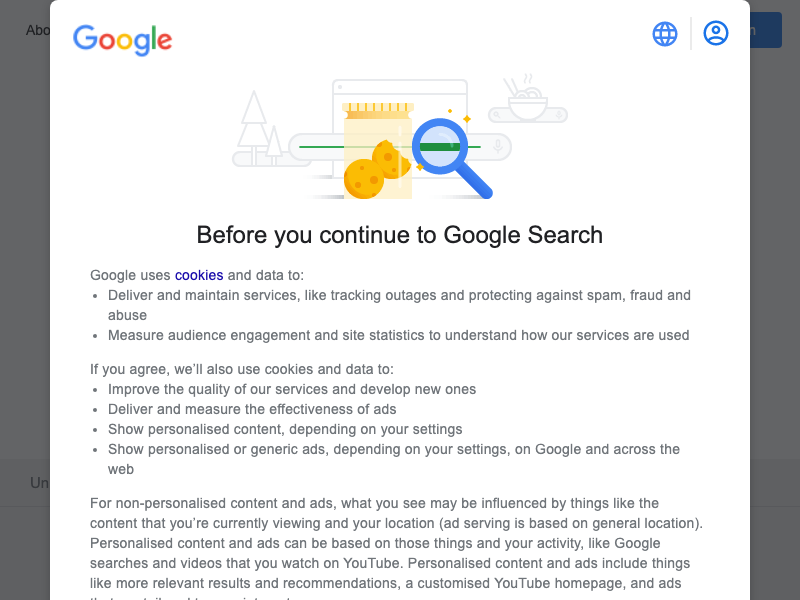
Problems#
However right now all we see is a giant popup window relating to cookie acceptance, and the resolution of the browser is too small to see anything. First let's make the window bigger, then go about trying to accept cookies. To make the window bigger you can pass in a defaultViewPort setting when launching puppeteer:
const browser = await puppeteer.launch({ defaultViewport: { width:1920, height:1080 } });Which will net you the following output:
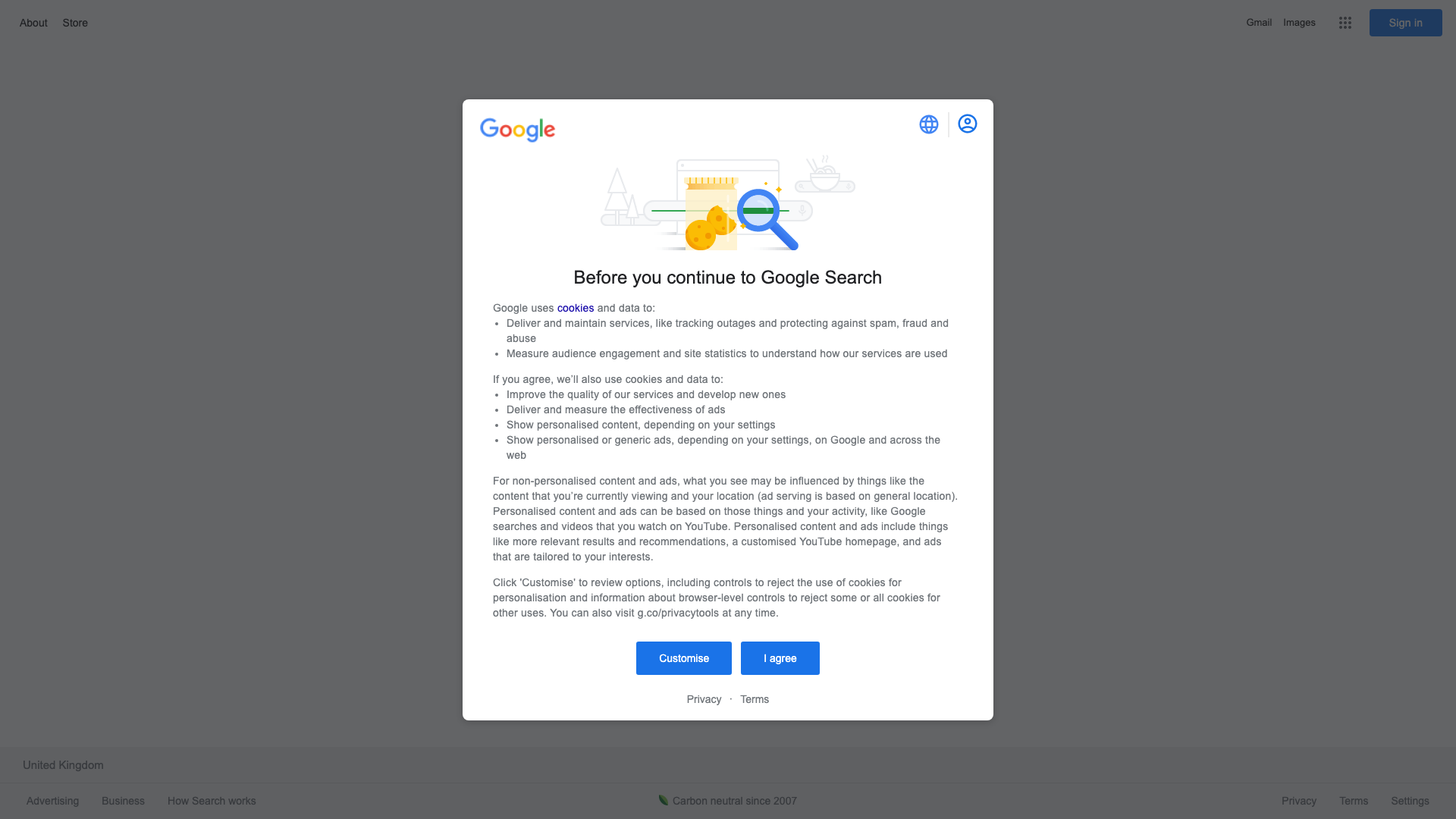
Now what?#
To interact with the button we need to find the button. Using document.queryElementAll('button') to get all buttons and trying to find the right one might be tricky. One option is to use XPath and select a button based on it's content "//button[contains(., 'I agree')]" and to use it with puppeteer:
const puppeteer = require('puppeteer'); async function screenshot() { const browser = await puppeteer.launch({ defaultViewport: { width:1920, height:1080 } }); const page = await browser.newPage(); await page.goto('https://www.google.com'); // Agree to cookies const [button] = await page.$x("//button[contains(., 'I agree')]"); if (button) { await button.click(); } await page.screenshot({path: 'GoogleOn' + new Date().toDateString() + '. png'}); browser.close(); } screenshot();Resulting in:
Now let's try doing something more complicated.
Scraping Google carousel results#
On certain topics, such as querying books from an author, google will present a carousel at the top displaying the author's books alongside a picture and date. For example, searching for 'roberto bolano books' may give the following:
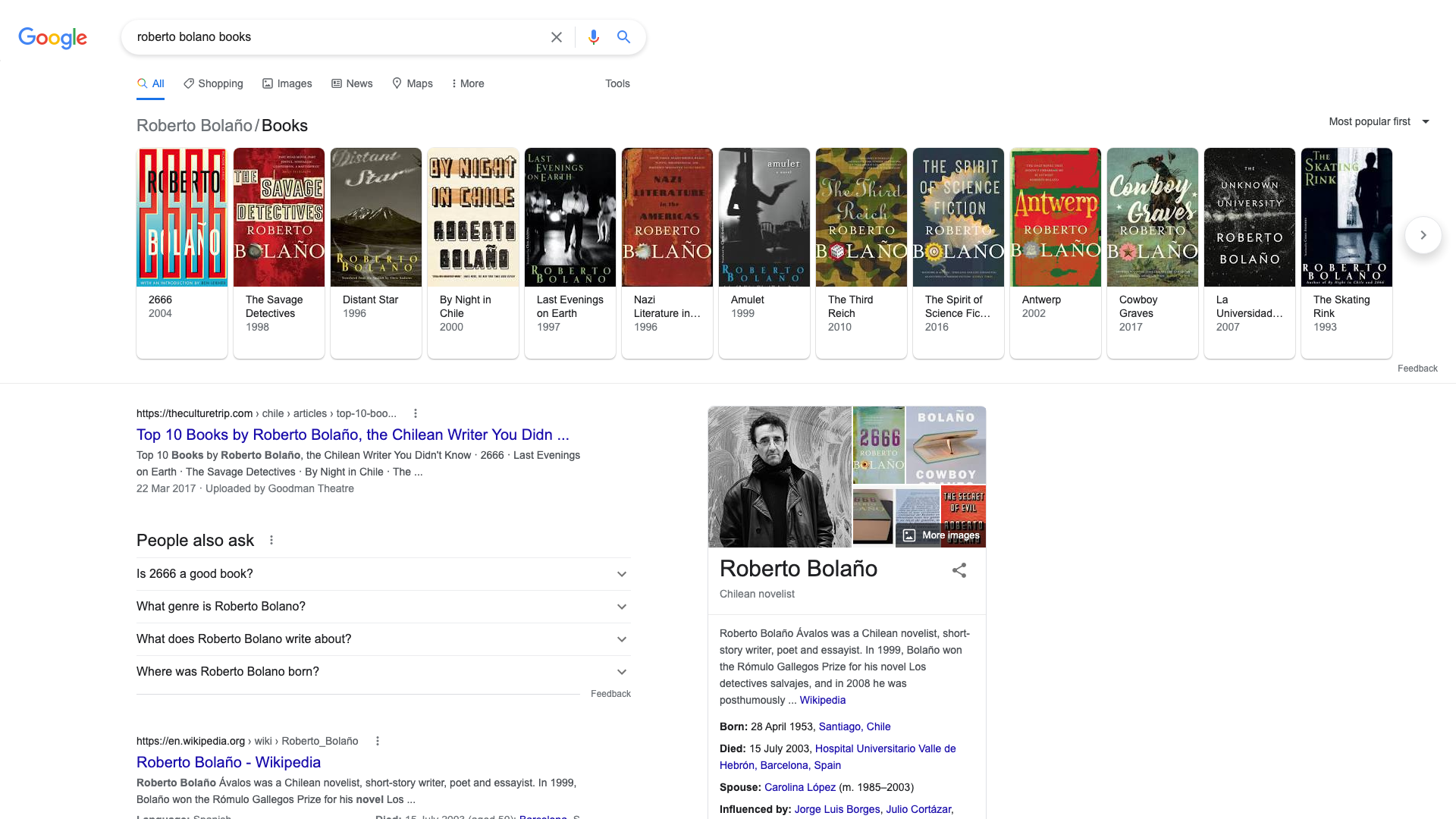
And if we want to build up a large collection of books given a list of authors, we can scrape the Google caoursel results, and we can do that quite easily with puppeteer. Perhaps the hard part is to reliably find the HTMLElement which contains the items you wish to scrape, as ids may not be consistent between visits or between different author searches. A great way to find items on the document is using SelectorGadget
const puppeteer = require('puppeteer');
async function scrape() { const browser = await puppeteer.launch({ defaultViewport: { width:1920, height:1080 } }); const page = await browser.newPage(); await page.goto('https://www.google.com/search?q=roberto+bolano+books');
// Agree to cookies let [button] = await page.$x("//button[contains(., 'I agree')]"); if (button) { await button.click(); }
const json = await page.evaluate(() => { const carousel = extabar.querySelector('.DAVP1');
const scrapedData = {}; scrapedData["Books"] = []; const items = carousel.children;
// Function to depth first search an HTMLElement for a property function getItemProperty(property) { return function getProp(item) { const childElementCount = item.childElementCount; if(!item[property]) { if(childElementCount === 0) { return ""; } else { for(let i=0; i<childElementCount; ++i) { const childLabel = getProp(item.children[i]); if(childLabel) { return childLabel; } } }
} else { return item[property]; }
return ""; } }
function getAriaLabel(item) { return getItemProperty('ariaLabel')(item); }
function getTitle(item) { return getItemProperty('title')(item); }
for (const item of items) { const label = getAriaLabel(item);
if(!label) { continue; }
const obj = {};
obj["name"] = label;
const itemTitle = getTitle(item);
// Get the extensions data such as book year from the difference // in item title and item aria-label if(itemTitle.length > label.length) { const details = itemTitle.substring(label.length + 2, itemTitle.length - 1); obj["extensions"] = details.split(', '); }
scrapedData["Books"].push(obj); }
return JSON.stringify(scrapedData, null, 2); });
console.log(json); browser.close();}
scrape();Results#
This manages to get us a JSON object containing all the book's showcased on Google's carousel. And you can imagine if you had a list of thousands of authors you could quickly get a huge database of books. Scraping pictures and links from the carousel is also possible which I did here as part of a coding challenge. But the output of the previous code is as follows:
{ "Books": [ { "name": "2666", "extensions": [ "2004" ] }, { "name": "The Savage Detectives", "extensions": [ "1998" ] }, { "name": "Distant Star", "extensions": [ "1996" ] }, { "name": "By Night in Chile", "extensions": [ "2000" ] }, { "name": "Last Evenings on Earth", "extensions": [ "1997" ] }, { "name": "Nazi Literature in the Americas", "extensions": [ "1996" ] }, { "name": "Amulet", "extensions": [ "1999" ] }, { "name": "The Third Reich", "extensions": [ "2010" ] }, { "name": "The Spirit of Science Fiction", "extensions": [ "2016" ] }, { "name": "Antwerp", "extensions": [ "2002" ] }, { "name": "Cowboy Graves", "extensions": [ "2017" ] }, { "name": "La Universidad Desconocida", "extensions": [ "2007" ] }, { "name": "The Skating Rink", "extensions": [ "1993" ] }, { "name": "The Romantic Dogs", "extensions": [ "1995" ] }, { "name": "Monsieur Pain", "extensions": [ "1984" ] }, { "name": "Woes of the True Policeman", "extensions": [ "2011" ] }, { "name": "The Insufferable Gaucho", "extensions": [ "2003" ] }, { "name": "The Return", "extensions": [ "2010" ] }, { "name": "Entre paréntesis", "extensions": [ "2004" ] }, { "name": "The Secret of Evil", "extensions": [ "2007" ] }, { "name": "A Little Lumpen Novelita", "extensions": [ "2002" ] }, { "name": "Putas Asesinas", "extensions": [ "2001" ] }, { "name": "Tres", "extensions": [ "2000" ] }, { "name": "Roberto Bolano: The Last Interview: And Other Conversations" }, { "name": "Consejos de un discípulo de Morrison a un fanático de Joyce", "extensions": [ "1984" ] }, { "name": "Antwerp (New Directions Pearls)", "extensions": [ "1958" ] } ]}Going Further#
Puppeteer let's you automate many web actions, have a look at the Puppeteer website for more info on getting started.